Why Every AI Workflow in Private Equity Starts with Memory Architecture
Feb 19, 2026

Every AI workflow is downstream of the information layer.
This is not a product claim. It is an architectural finding — one that has emerged independently across dozens of research groups and is now considered foundational consensus in the AI agent literature.
In December 2025, a 47-author collaboration spanning Tsinghua, Oxford, and Fudan published the most comprehensive survey to date on AI agent memory systems — "Memory in the Age of AI Agents" (arXiv:2512.13564). Its central conclusion:
"Memory has emerged, and will continue to remain, a core capability of foundation model-based agents... Without persistent, structured memory, agents cannot reason across sessions, cannot maintain entity awareness, and cannot learn from prior experience."
— Hu et al., "Memory in the Age of AI Agents," arXiv:2512.13564 (Dec. 2025)
A parallel finding from the Mem0 paper (arXiv:2504.19413, 2025) — which benchmarked the leading memory architectures in production — frames the failure mode with precision:
"Unlike humans, who dynamically integrate new information and revise outdated beliefs, LLMs effectively 'reset' once information falls outside their context window. Even models with 200K-token context windows merely delay rather than solve this problem."
— Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory (2025)
This is the precise mechanism causing off-the-shelf AI products to fail in private equity workflows. Tools like Copilot have sophisticated retrieval and summarization systems — but they have no persistent model of your firm. Each query is a cold start. Each document is processed in isolation. The system has no entity awareness: it cannot connect the "Target Co" in today's VDR to the same company it saw in a deal two years ago. It has no schema memory: it does not know how your firm defines adjusted EBITDA, or which line items belong in your IC memo, or how your healthcare team thinks about payor mix risk. Every session, the model resets.
The literature identifies four failure modes that are structurally guaranteed in any system that lacks a persistent information layer — and which map precisely to the complaints PE practitioners raise about existing tools:
Single-pass retrieval. The tool searches once for what looks relevant rather than methodically reasoning across documents the way a trained analyst would. The A-MEM paper (NeurIPS 2025) formalizes this: memory systems that lack dynamic linking between related entries produce outputs that are accurate in isolation but incoherent in context.
No entity awareness. Without a persistent entity graph, the system treats every name, company, and person as isolated text. It cannot recognize that "Acme Services" and "Acme Holdings" are the same company, or that the CEO who appeared in a 2022 CIM is now the CFO of a portfolio company. The Zep paper (Jan. 2025) demonstrates that temporal knowledge graphs — which track entities and their relationships over time — produce fundamentally more reliable outputs than flat-vector retrieval systems.
Structural blindness. Standard RAG systems process documents as flat text. They have no understanding of tables, footnotes, or how financial documents are organized — critical failure modes in VDR analysis, where a footnote frequently modifies the headline number it references.
No cross-document reasoning. Without a memory layer, the system starts from scratch on every query. It does not know your IC template, how you define adjusted EBITDA, what sectors you've seen before, or how your team thinks about deals. The MemGPT paper (Packer et al., 2023 — now operationalized as Letta) established the foundational architecture for treating memory as a first-class component: agents that manage their own memory as an operating system manages RAM, with structured read/write operations rather than passive context windows.
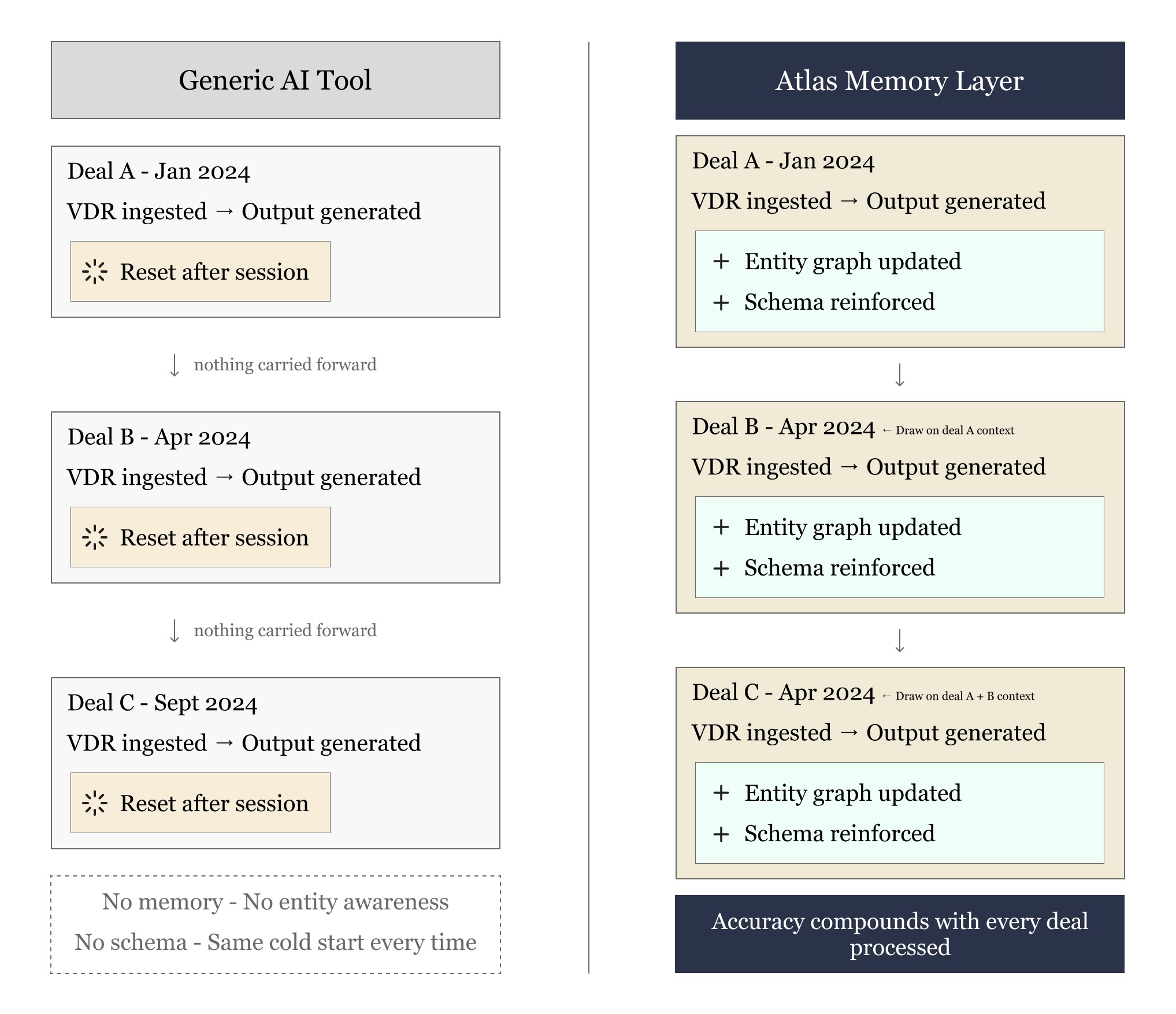
How Atlas implements the research.
Clarus's memory layer — Atlas — is built on the architectural principles that have emerged as best practice in the most rigorous recent literature. Specifically, Atlas implements a five-layer memory stack aligned to the taxonomy proposed in the 2025 agent memory survey literature.
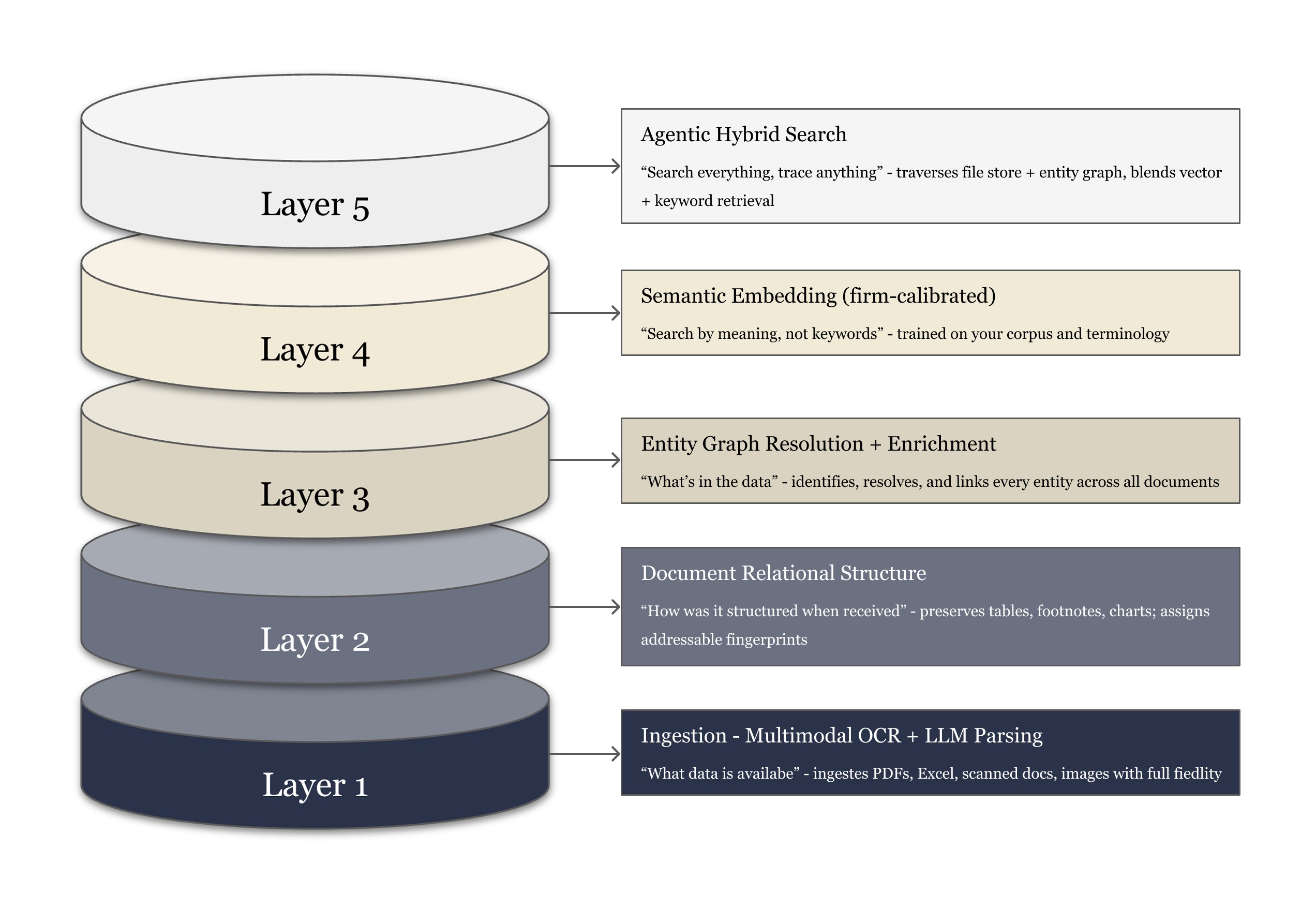
Layer 1 & 2: Multimodal Ingestion and Structural Preservation
Most retrieval systems extract text and discard structure. Atlas preserves the relational structure of every document — tables are stored as tables, footnotes as modifiers of their referenced values, charts as data points with provenance labels. Every page element receives an addressable fingerprint so any downstream insight can be traced back to its exact source document, page, and element.
This matters in PE because the financial data that drives investment decisions almost always lives in table cells, footnote adjustments, and exhibit columns — not in paragraphs. A system that reads a 10-K as flat text and a system that reads it as structured financial data are not running the same analysis.
Layer 3: Entity Graph Resolution
Atlas maintains a persistent knowledge graph of every entity that matters to the firm — companies, funds, management teams, counterparties, legal entities, and the temporal relationships between them. This is the implementation of what the Zep paper (Baxter et al., Jan. 2025) calls a temporal knowledge graph: a structured memory that tracks not just what entities exist, but when relationships were established, when they changed, and what can be inferred from those changes.
In practice: when "Acme Services" appears in a new VDR, Atlas does not treat it as new information. It resolves the entity against the existing knowledge graph, retrieves prior deal history, ownership structure, management team, and any prior marks — and surfaces all of this as context for the current analysis. The A-MEM paper (NeurIPS 2025) describes this architecture as an "interconnected knowledge network through dynamic indexing and linking" that "enables memory graphs to mirror human associative learning."
Layer 4: Firm-Calibrated Semantic Embeddings
Standard semantic search is trained on general corpora. The embedding model that powers a generic AI tool has never seen a private equity IC memo, does not know what "adjusted EBITDA" means in a buyout context versus a credit context, and has no sense of what risk language looks like in a healthcare deal versus an industrials deal.
Atlas's embedding layer is calibrated on the firm's own corpus — its historical memos, prior deal documents, and internal communications. The result is that semantic search retrieves results based on how your team talks about performance, risk, and opportunity — not how the general internet talks about those concepts. The Mem0 research formalizes this: graph-enhanced memory representations "better model complex relationships between conversational elements" and outperform flat vector approaches across every benchmark evaluated.
Layer 5: Compounding Accuracy via Temporal Reasoning
The most important property of Atlas — and the one that most directly differentiates it from generic tools — is that accuracy improves over time. The agent memory survey literature identifies what one paper calls the "experience-following property": empirical studies show that "high input similarity between query and memory strongly biases output similarity, making memory management quality essential for robust long-term performance" (Zhang et al., 2025).
In plain terms: a memory system that has already processed 50 of your deals produces more accurate outputs on deal 51 than it did on deal 1. The entity graph is richer. The schema calibration is tighter. The extraction logic has been refined by feedback. The system is not reset; it is trained on your firm's own experience.
Healthcare PE Firm: IC Memo Generation at Scale
A healthcare-focused middle market private equity firm was evaluating 400+ inbound deals per year. Every deal required a standardized investment committee memo — but VDR quality ranged from polished data rooms to bare-bones Google Drives with a pitch deck and two months of unaudited financials. The result was that memo production time was determined more by founder packaging discipline than by deal quality.
The Problem
4–6 analyst hours per initial screening memo, regardless of deal stage or quality
Output inconsistency across analysts — different section ordering, different financial summary structures, different definitions of adjusted EBITDA applied informally
No cross-deal pattern recognition — the team had no systematic way to compare how a new healthcare services deal mapped against prior deals in the same sub-vertical
Generic AI tools evaluated and rejected — the team piloted off-the-shelf solutions and found that outputs required nearly as much manual revision as starting from scratch, because neither tool understood the firm's IC format, sector KPIs (payor mix, reimbursement exposure, EBITDA adjustments for management fees), or risk language
"The tool doesn't know our IC template, how we define adjusted EBITDA, or our sector comp framework. Every deal is a cold start — we're re-prompting the same logic we set up six months ago."
— Principal, Upper Mid-Market Healthcare PE (prior to Clarus engagement)
The Deployment
Atlas was deployed before a single deal was processed. The knowledge mapping phase captured:
IC memo template: all required sections, field definitions, section ordering, and qualitative rubrics for healthcare deal evaluation
Sector schema: the firm's specific definitions of adjusted EBITDA across healthcare services, life sciences, and medtech sub-verticals; payor mix classification methodology; and reimbursement sensitivity framework
Entity graph initialization: historical deals, management teams, advisors, sponsors, and counterparties the firm had encountered — so that entity resolution would have a foundation from day one
VDR ingestion rules: handling logic for the range of document formats the firm actually receives, including unstructured Google Drives, scanned documents, and pitch decks that substitute for proper CIMs
With Atlas calibrated, Clarus activated Apex — the document workflow engine — tuned to this firm's IC memo generation workflow. The system was explicitly designed to handle reality: not the polished CIM, but the full distribution of what founders send.
The Results
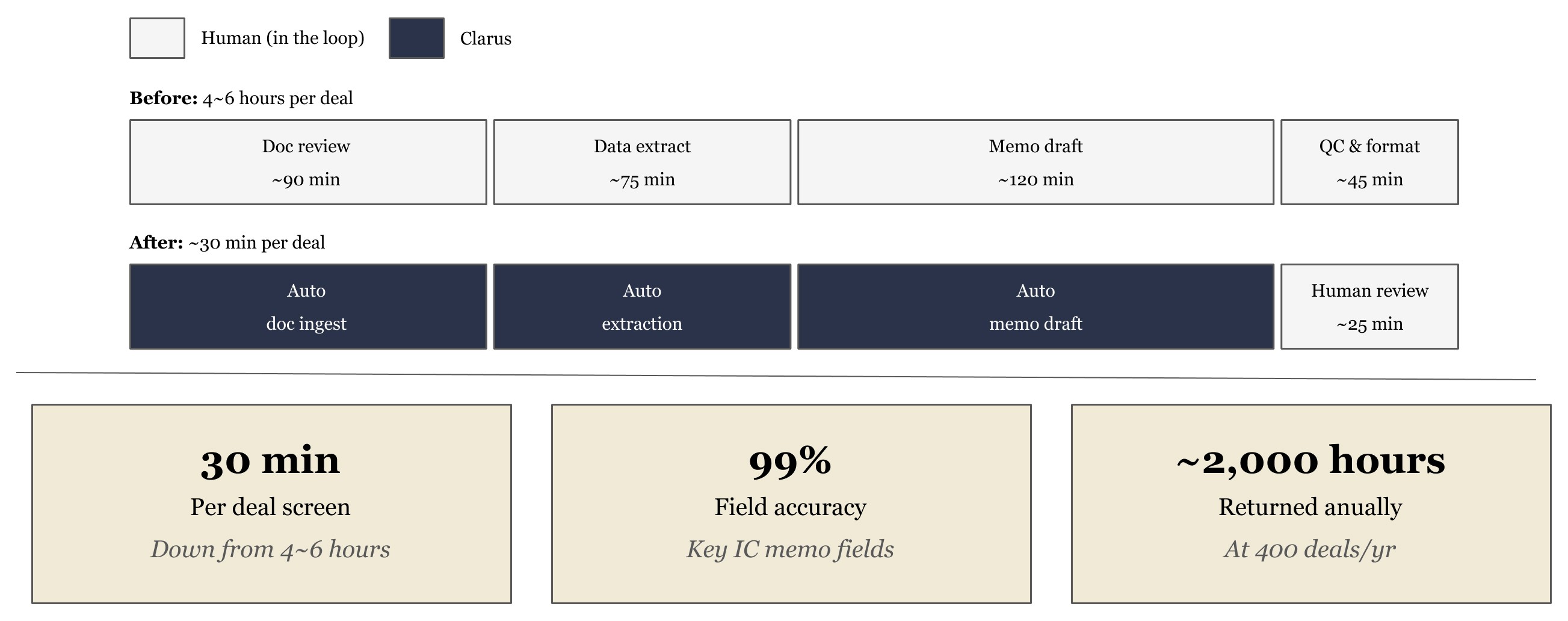
Three structural improvements beyond headline time savings:
Consistency at scale. Every memo, regardless of analyst or VDR quality, came out in the same structure — enabling IC members to compare deals side-by-side without re-orienting to different formats. This is the direct output of Atlas's schema memory: the system enforces the firm's own output format as a hard constraint, not a suggestion.
Compounding accuracy. Each new deal processed made Atlas more accurate on the next. Entity relationships updated, sector extraction patterns reinforced, edge cases resolved forward. This is the experience-following property identified in the research literature, operationalized in a production PE environment.
Analyst reallocation. Associates who previously spent 4–6 hours on initial document review now spend that time on the analytical judgment that requires a human: assessing management quality, evaluating competitive positioning, and stress-testing model assumptions. The information extraction is automated; the investment judgment is not.
The moat is the memory layer.
Generic AI tools fail in private equity for the same structural reason they fail in any specialized domain: they have no model of how a specific firm thinks. The MemGPT paper established the core architectural principle — LLMs should manage memory the way an operating system manages storage, with structured long-term storage that persists across sessions, not a context window that resets with every query.
The agent memory survey literature identifies what differentiates persistent-memory architectures from context-window-based approaches in production settings. The gap is not marginal. Systems with structured, persistent memory outperform context-only systems on every meaningful metric once the task requires cross-document reasoning, entity tracking, or domain-specific schema adherence — all of which describe virtually every workflow in private equity.
Atlas is Clarus's implementation of this foundation. It is not a workflow feature — it is the precondition for every workflow built on top of it. Apex (document workflows), Prism (portfolio monitoring), and Lattice (Excel workflows) all run on Atlas. The information layer is upstream of everything.
The key insight, drawn directly from the research: memory quality is not a nice-to-have property of AI agents. It is the primary determinant of output accuracy in any domain where tasks require reasoning across multiple documents, entities, or time periods. Private equity is exactly that domain.