How a Global Private Markets Firm Automated a Week-Long Fund Workflow with Clarus
Jan 22, 2026

In private markets, some of the most time-consuming work isn’t the investment decision itself—it’s the operational reality of turning messy documents into structured, review-ready outputs.
One private markets investment firm was running a workflow that routinely took about a week of combined effort across operations and the investment team. And it didn’t only show up at quarter-end.
The same manual work appeared in two critical places:
Ongoing monitoring of fund investments (every quarter)
Underwriting new fund opportunities (fund-of-funds and secondaries)
This post explains what that workflow looked like, why “automated parsing” promises failed in practice, and how the firm used Clarus to automate the last mile.
The Firm
The client is a private markets investment platform with exposure across fund investments and secondary transactions, and a disciplined approach to identifying high-quality managers and opportunities. The team runs a high-touch process where investment judgment depends on having clean, consistent data inside the templates they trust.
The Problem: A Week of Manual Work—Across Monitoring and Underwriting
The core workflow was the same in both monitoring and underwriting:
Input: 200~400 pages of quarterly reports, SOIs, capital account statements, notices, and supporting PDFs per monitoring cycle
Output: structured tables and a standardized workbook used for analysis, reporting, and decision-making
Where the time went: Quarterly monitoring
Each quarter, the team had to monitor existing fund investments by pulling key information from quarterly materials and updating internal templates. That meant:
collecting and validating the right set of documents
extracting positions and valuation changes
normalizing dates/currencies/naming conventions
reconciling inconsistencies across sources
preparing review-ready outputs for the investment team
Where the time went: Underwriting new opportunities (FoF / secondaries)
During underwriting, the same problem repeated—often under tighter deadlines:
parsing deal materials and portfolio/fund documentation
converting unstructured PDFs into structured tables
populating internal underwriting templates
QA’ing edge cases and footnotes with the investment team
Across both workflows, “automation” wasn’t blocked by lack of access to docs—it was blocked by the difficulty of producing repeatable, trustworthy structured outputs.
Net effect: this workflow routinely consumed ~a week across Operations and the investment team—every quarter for monitoring, and repeatedly during underwriting cycles.
Why the "Parsing" Feature Never Delivered
The firm had already deployed software that worked well for document retrieval—collecting, organizing, and finding documents.
That platform also promised automated parsing to automate downstream workflows. In reality, it never reached production-grade reliability:
outputs were inconsistent across managers and formats
edge cases regularly broke extraction
“human cleanup” erased the value of automation
after nearly a year, the team still couldn’t rely on it for real execution
So the retrieval layer existed—but the structured workflow still required manual effort.
Retrieval is not automation. The bottleneck remained: turning PDFs into clean, template-ready data.
General-purpose AI agents
The firm also tested general-purpose tools including Shortcut AI, Claude’s Excel agent, and similar products with sanitized documents.
These failed at production scale for a specific reason: context limits.
A typical quarterly monitoring cycle involves hundreds of pages across dozens of documents. When a single agent tries to discover all investments, plan every row, and populate the sheet, it hits fundamental limits:
prompts grow too large for the model to handle reliably
runs slow down significantly
accuracy degrades when the model juggles too many rows simultaneously
the volume of information these systems need to process exceeds what they were built for
In one test, the team found that a general-purpose agent made a $2.3 million valuation error by misattributing a distribution notice to the wrong fund—an error that would have required the same manual review process they were trying to eliminate.
Why Off-the-Shelf AI Agents Fail at This Scale
The firm’s experience reflects a fundamental architectural limitation in most AI-powered document processing tools.
The single-agent problem
Most tool attempt to run one agent that:
discovers all investments in the document set
plans every row that needs to be populated
fills the entire sheet
This approach works for demos with 5~10 documents. It breaks down with 50+ fund relationships and hundreds of pages because:
Context window limits: The model can only “see” so much at once
Attention degradation: Accuracy drops when tracking many items simultaneously
No isolation: One mistake in row 15 can cascade to corrupt row 47
What production-grade automation requires
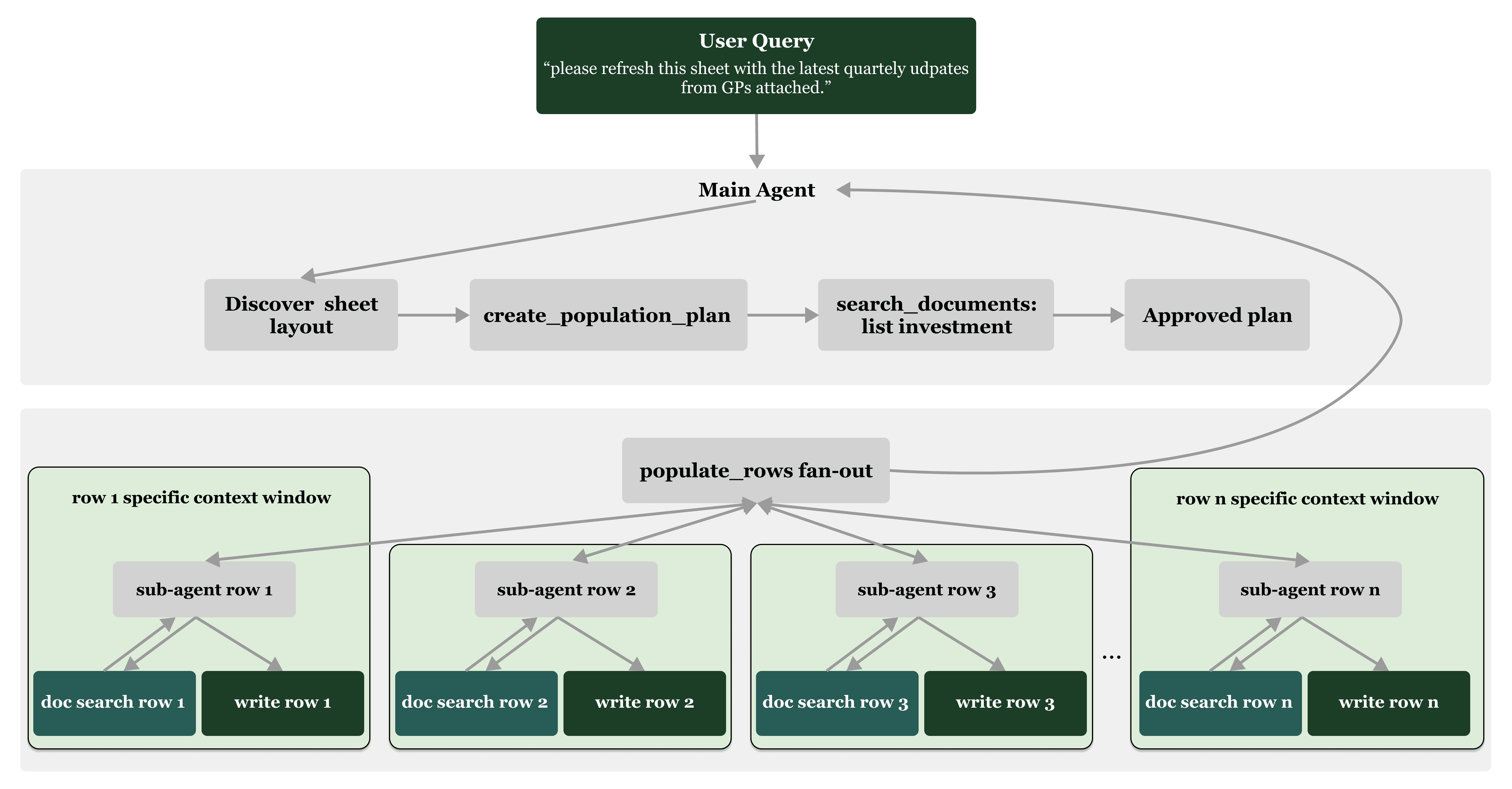
Instead of asking one agent to do everything, production systems need a planner/executor architecture:
A main agent discovers the sheet layout and searches documents to identify all investments
It builds a population plan listing every row to fill
Once approved, it spawns a focused sub-agent for each row
Each sub-agent handles only its row—searching the relevant documents, pulling values, and writing to the sheet
This matters because:
Smaller context per row → fewer hallucinations, better accuracy
Parallel execution → faster end-to-end runs
Row-level traceability → each row has its own search/results summary, making audit straightforward
What the Team Needed Instead
They weren’t looking for another demo. They needed something that could survive real execution in monitoring and underwriting:
Firm-specific rules, not generic templates
Repeatability across managers, vintages, and deal packages
Validation + exception handling, not “best-effort parsing”
Traceability back to source documents for review
The Clarus Approach: Automate the Workflow They Already Trust
The team partnered with Clarus to automate the end-to-end workflow from messy fund documents to their internal templates.
Clarus was built to plug into the firm’s existing process—not replace it.
Inputs
quarterly fund documents already housed in the firm’s retrieval system
underwriting materials for new FoF/secondaries opportunities
supporting schedules as available
Processing
Clarus runs a structured pipeline designed for messy, real-world inputs:
extract key tables and fields from quarterly and deal documents
normalize formatting (dates, currencies, numeric fields, naming)
apply the firm’s rules for how investments should be represented
e.g., row granularity, fund vs portfolio classification, security handling
reconcile conflicts with explicit precedence logic
e.g., “most recent as-of date wins” for valuations
run validations and flag exceptions for human review
preserve traceability back to source documents for QA
Outputs
completed templates/workbooks in the same format the team already uses
a reviewable set of exceptions rather than a week of manual assembly
What Changed Operationally
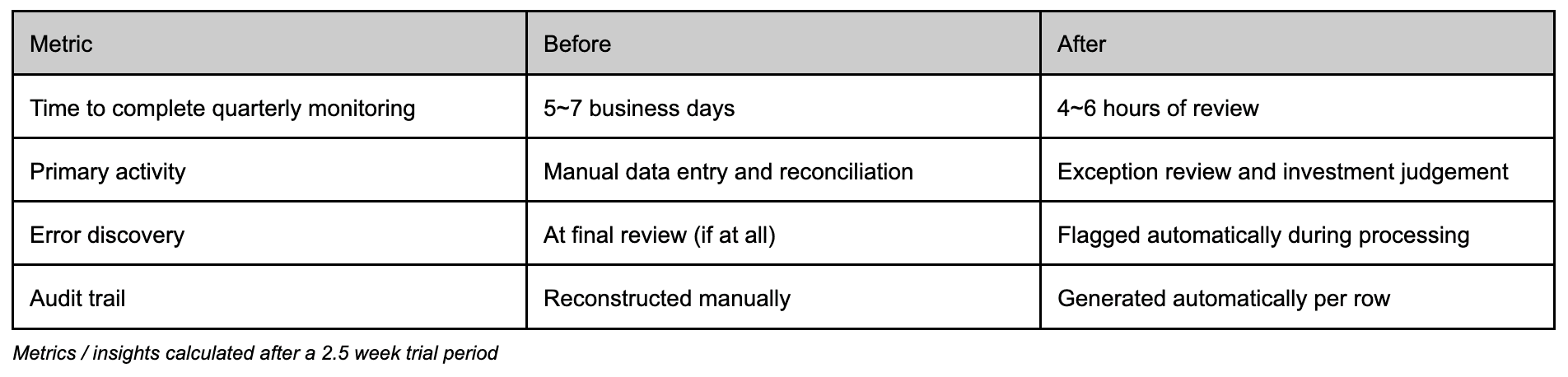
Before: the team spent most of its time constructing the dataset—copying, formatting, normalizing, and reconciling.
After: the team spends time reviewing and approving a largely pre-populated output, focusing on exceptions and investment judgment rather than manual entry.
This shifted the process from “weeks of rework risk” to a workflow that’s repeatable in both:
quarterly monitoring, and
underwriting cycles for new FoF/secondaries opportunities
The Takeaway
Even with retrieval solved, the hard part remains: making data inside PDFs reliably usable inside the templates that drive monitoring and underwriting.
Generic parsing tools often fail not because they can’t extract text, but because they can’t consistently handle:
variation across managers and formats
edge cases in footnotes and disclosures
strict internal template requirements
the need for validations, provenance, and repeatability
Clarus focused on that last mile: automating a workflow that runs reliably in production—across both recurring monitoring and underwriting.
Clarus builds firm-specific automation for private markets teams—turning fund documents into structured, validated outputs inside the templates you already use. If you’re dealing with the same “retrieval is solved, parsing isn’t” gap, let’s talk.